


.jpg)
Informatics 2024, 11(1), 5; https://doi.org/10.3390/informatics11010005 (registering DOI) - 15 Jan 2024
Abstract
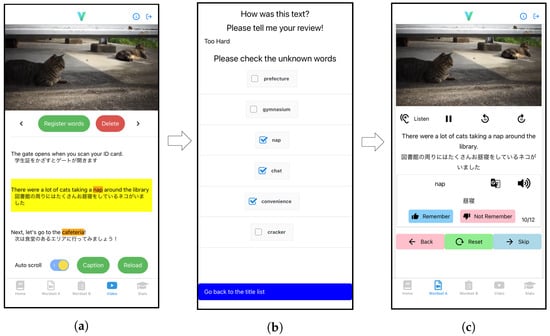
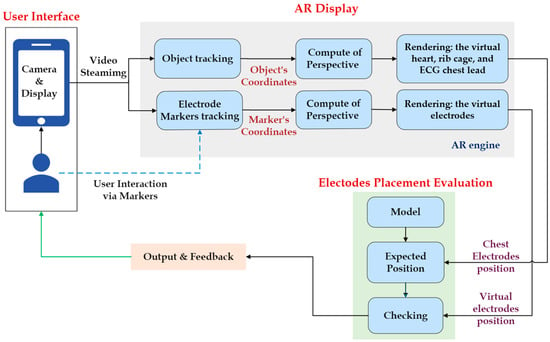
This study presents an augmented reality application for training chest electrocardiography electrode placement. AR applications featuring augmented object displays and interactions have been developed to facilitate learning and training of electrocardiography (ECG) chest lead placement via smartphones. The AR marker-based technique was used
[...] Read more.
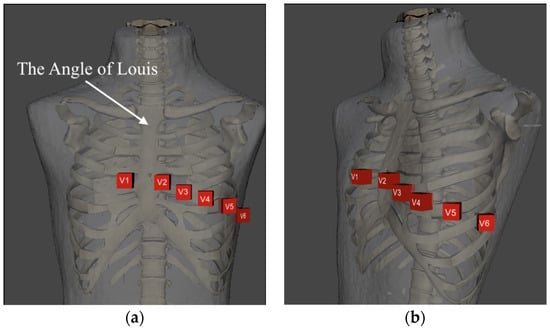
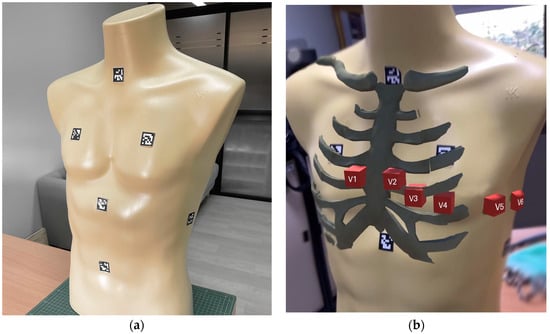
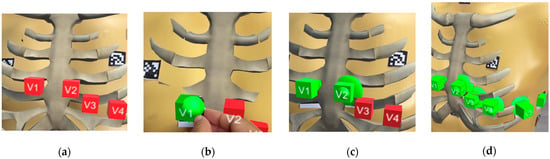
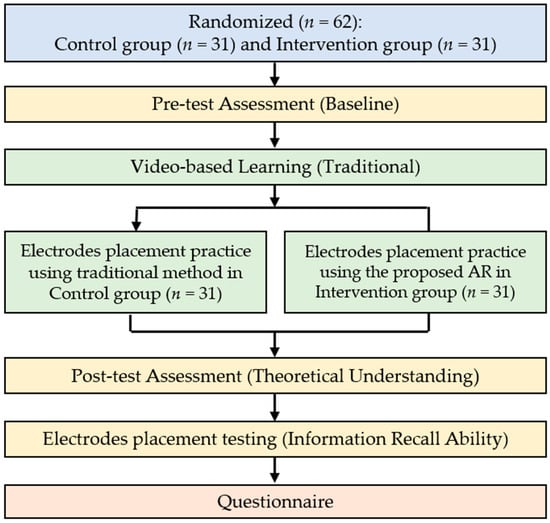
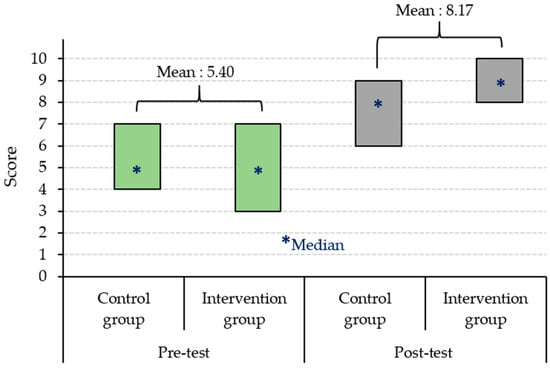
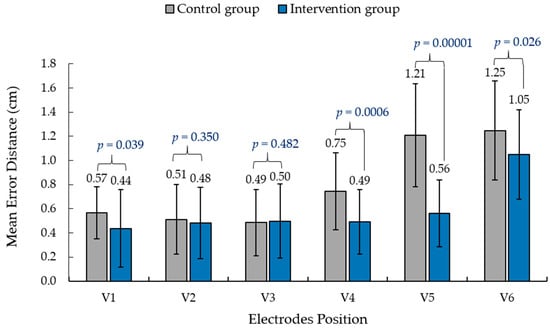
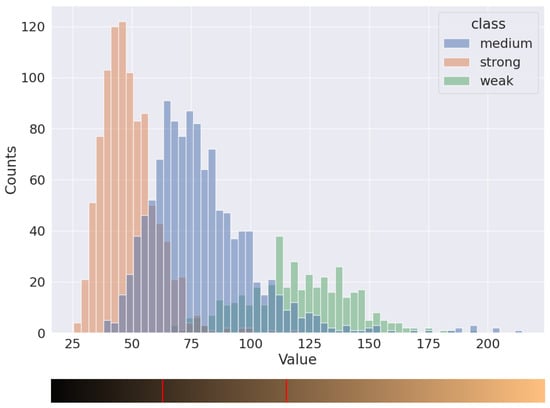
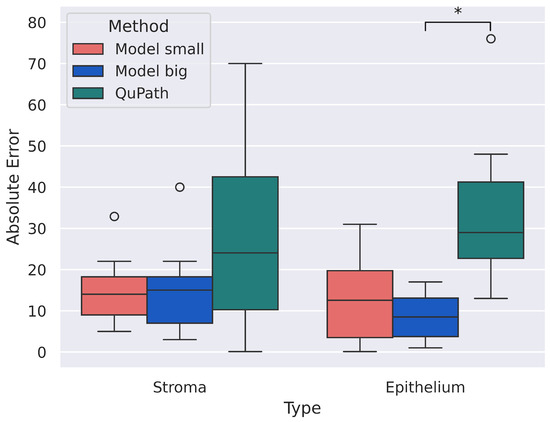
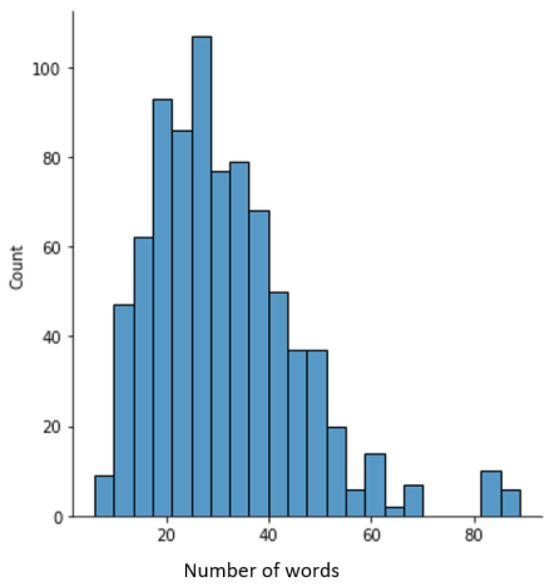
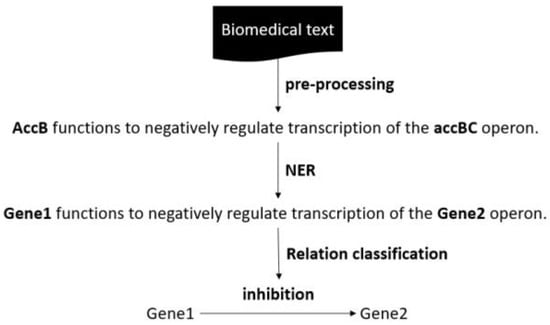
This study presents an augmented reality application for training chest electrocardiography electrode placement. AR applications featuring augmented object displays and interactions have been developed to facilitate learning and training of electrocardiography (ECG) chest lead placement via smartphones. The AR marker-based technique was used to track the objects. The proposed AR application can project virtual ECG electrode positions onto the mannequin’s chest and provide feedback to trainees. We designed experimental tasks using the pre- and post-tests and practice sessions to verify the efficiency of the proposed AR application. The control group was assigned to learn chest ECG electrode placement using traditional methods, whereas the intervention group was introduced to the proposed AR application for ECG electrode placement. The results indicate that the proposed AR application can encourage learning outcomes, such as chest lead ECG knowledge and skills. Moreover, using AR technology can enhance students’ learning experiences. In the future, we plan to apply the proposed AR technology to improve related courses in medical science education.
Full article
(This article belongs to the Section Human-Computer Interaction)
►
Show Figures
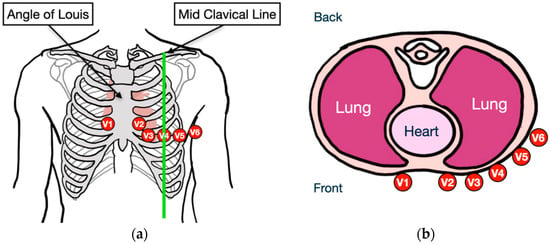
Figure 1






.jpg)





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
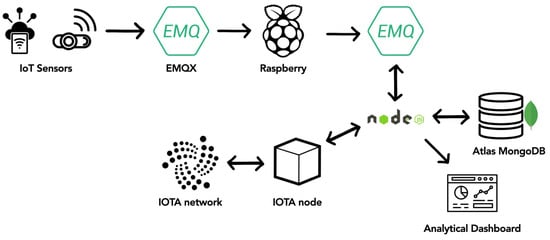{kind=link}
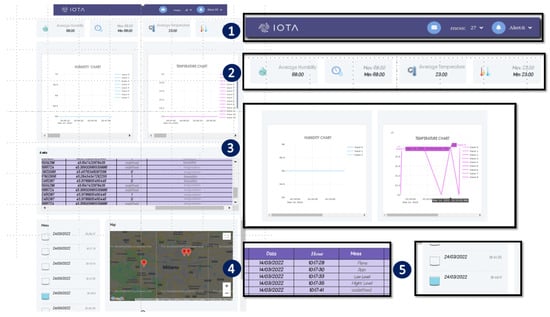{kind=link}
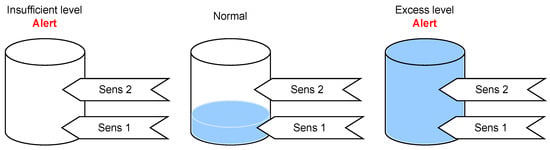{kind=link}
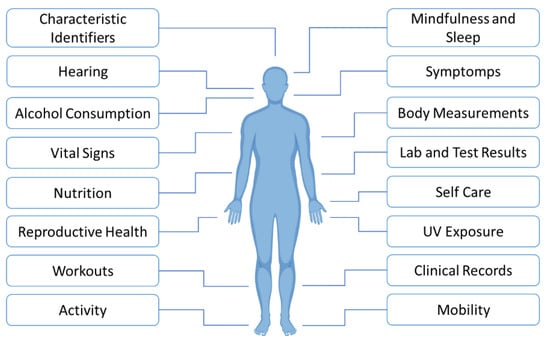{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
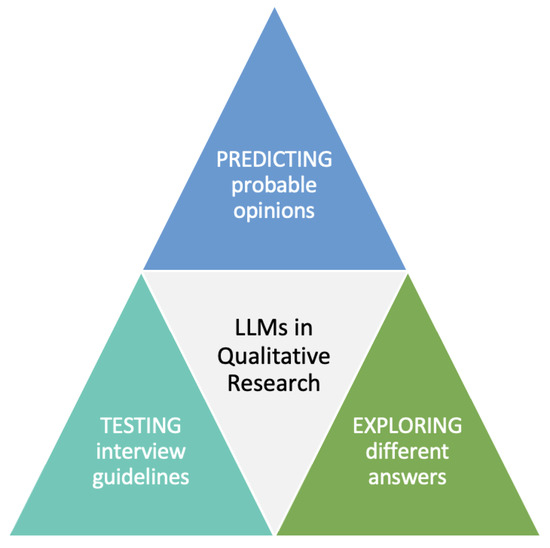{kind=link}
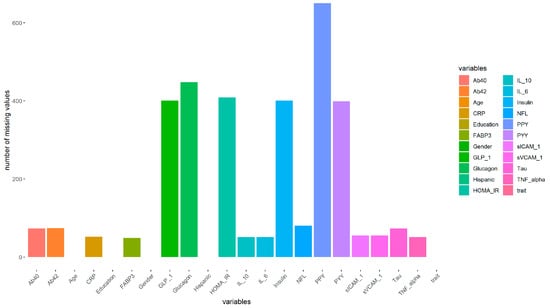{kind=link}
{kind=link}
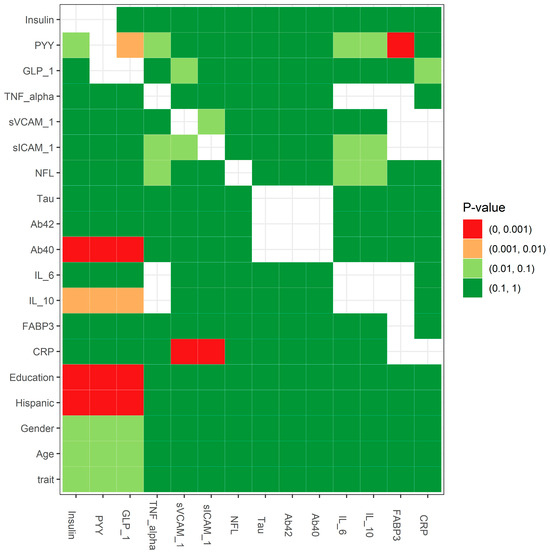{kind=link}
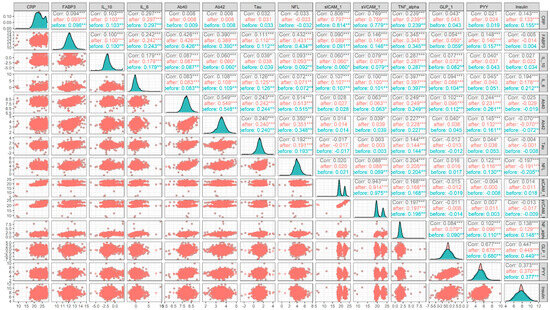{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}