




by
, , , , , and

Information 2024, 15(1), 48; https://doi.org/10.3390/info15010048 - 15 Jan 2024
Abstract
Bioinformatics and genomics are driving a healthcare revolution, particularly in the domain of drug discovery for anticancer peptides (ACPs). The integration of artificial intelligence (AI) has transformed healthcare, enabling personalized and immersive patient care experiences. These advanced technologies, coupled with the power of
[...] Read more.
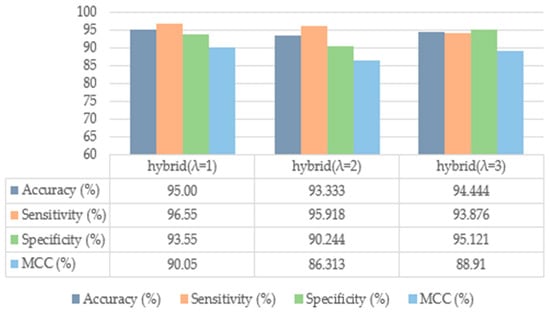
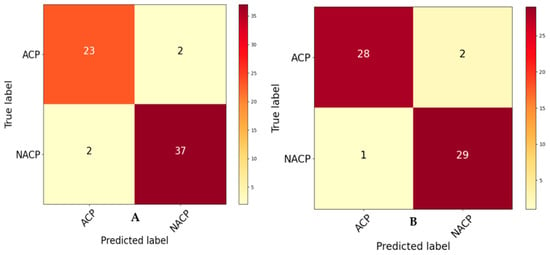
Bioinformatics and genomics are driving a healthcare revolution, particularly in the domain of drug discovery for anticancer peptides (ACPs). The integration of artificial intelligence (AI) has transformed healthcare, enabling personalized and immersive patient care experiences. These advanced technologies, coupled with the power of bioinformatics and genomic data, facilitate groundbreaking developments. The precise prediction of ACPs from complex biological sequences remains an ongoing challenge in the genomic area. Currently, conventional approaches such as chemotherapy, target therapy, radiotherapy, and surgery are widely used for cancer treatment. However, these methods fail to completely eradicate neoplastic cells or cancer stem cells and damage healthy tissues, resulting in morbidity and even mortality. To control such diseases, oncologists and drug designers highly desire to develop new preventive techniques with more efficiency and minor side effects. Therefore, this research provides an optimized computational-based framework for discriminating against ACPs. In addition, the proposed approach intelligently integrates four peptide encoding methods, namely amino acid occurrence analysis (AAOA), dipeptide occurrence analysis (DOA), tripeptide occurrence analysis (TOA), and enhanced pseudo amino acid composition (EPseAAC). To overcome the issue of bias and reduce true error, the synthetic minority oversampling technique (SMOTE) is applied to balance the samples against each class. The empirical results over two datasets, where the accuracy of the proposed model on the benchmark dataset is 97.56% and on the independent dataset is 95.00%, verify the effectiveness of our ensemble learning mechanism and show remarkable performance when compared with state-of-the-art (SOTA) methods. In addition, the application of metaverse technology in healthcare holds promise for transformative innovations, potentially enhancing patient experiences and providing novel solutions in the realm of preventive techniques and patient care.
Full article
(This article belongs to the Special Issue Applications of Deep Learning in Bioinformatics and Image Processing)
►
Show Figures

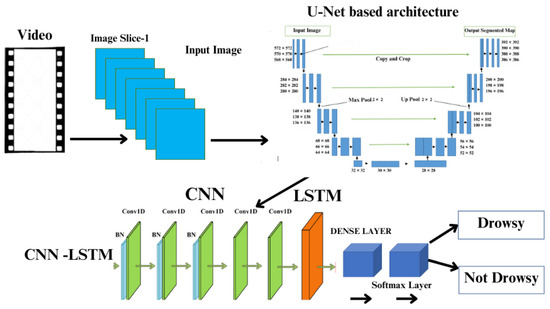
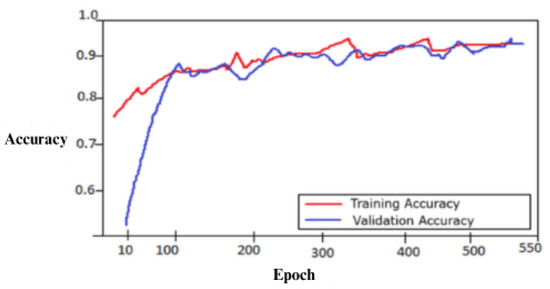
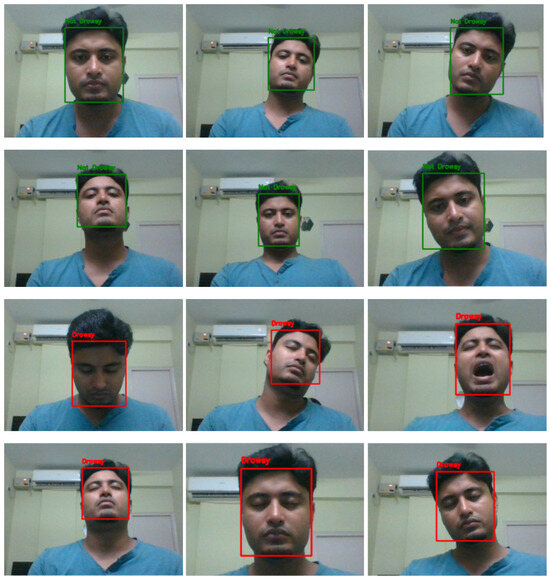
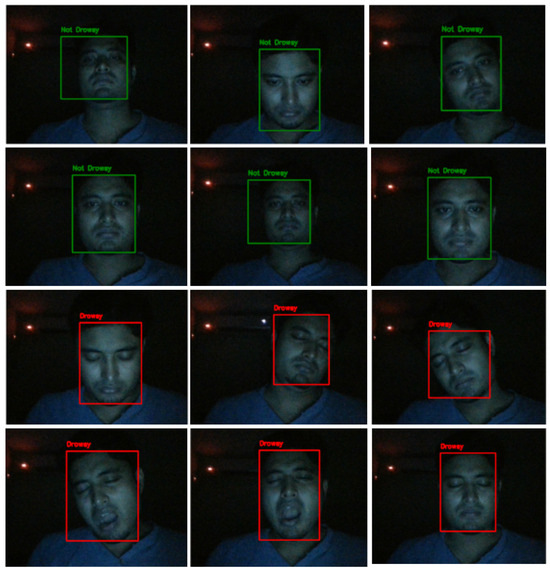
Figure 1





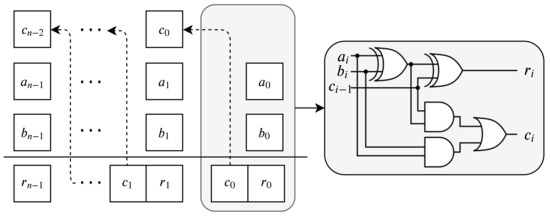


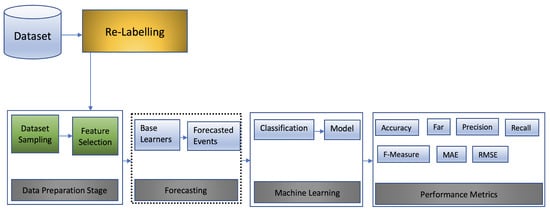









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}