






J. Imaging 2024, 10(1), 22; https://doi.org/10.3390/jimaging10010022 - 15 Jan 2024
Abstract
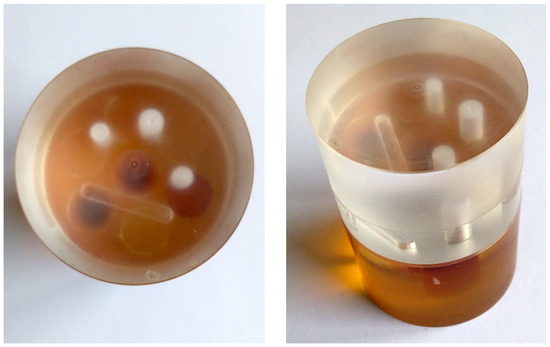
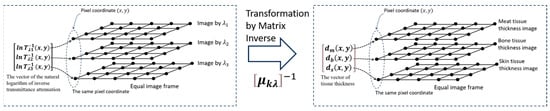
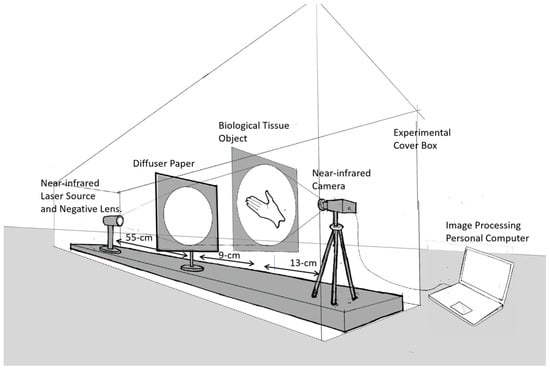
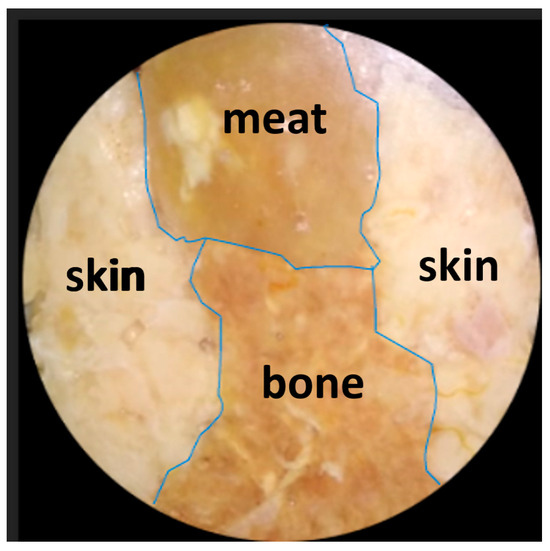
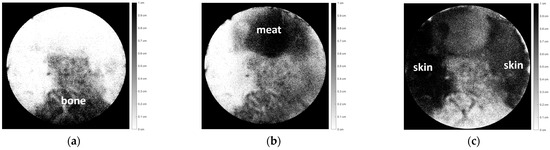
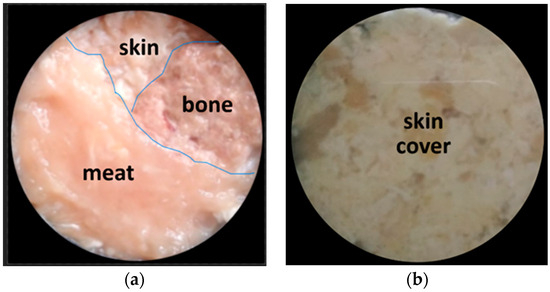
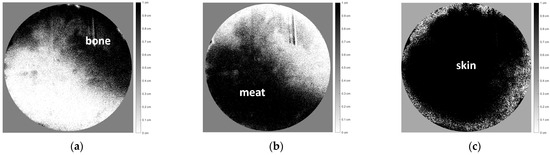
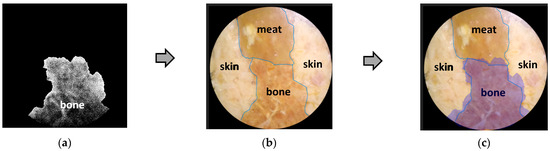
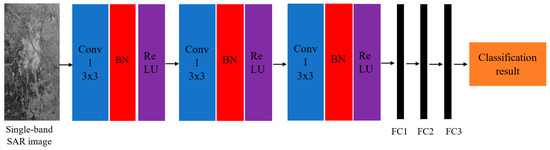
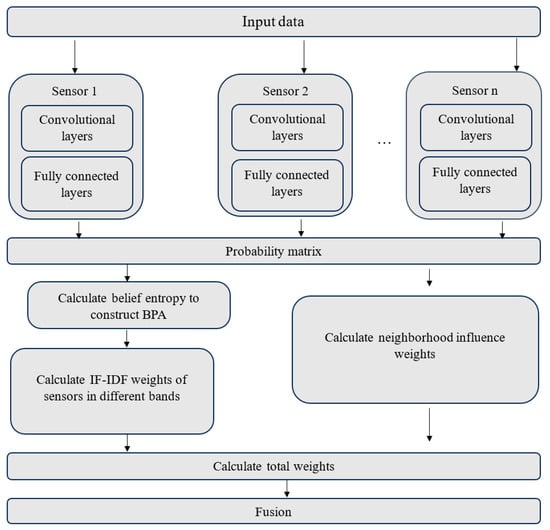
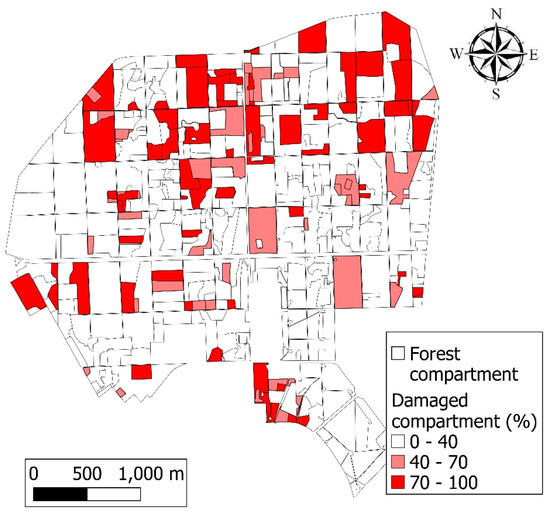
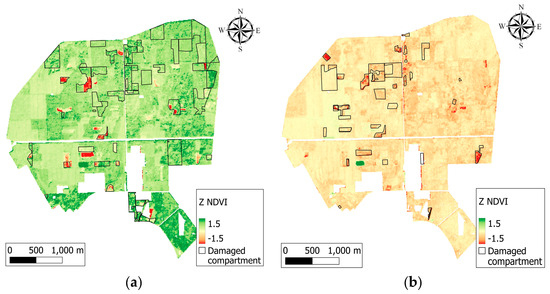
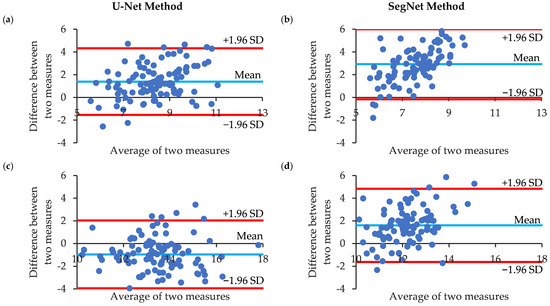
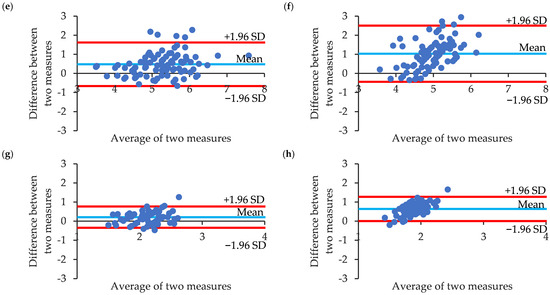
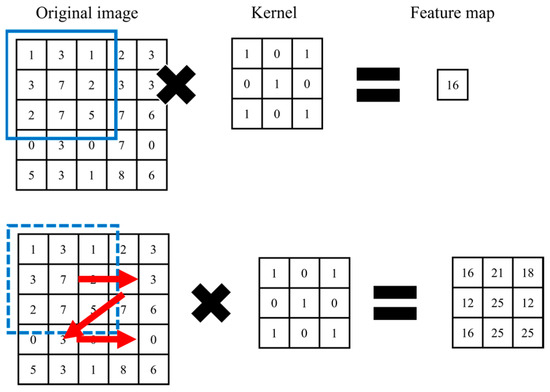
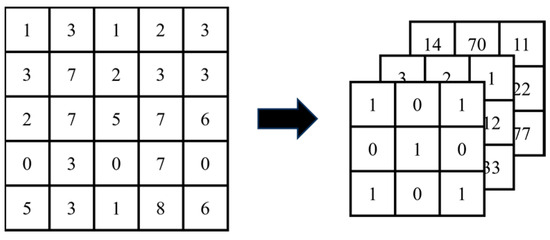
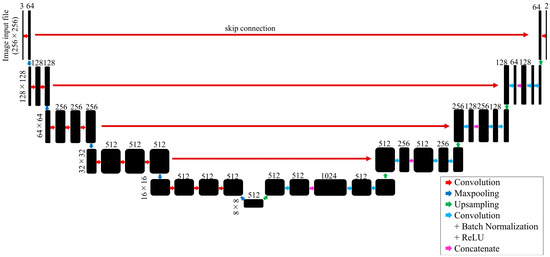
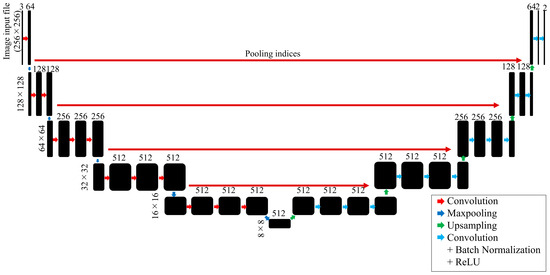
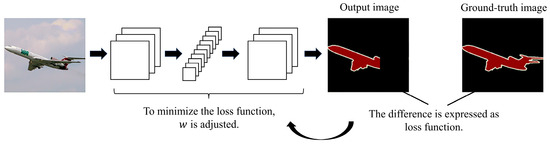
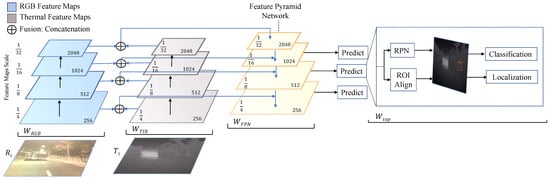
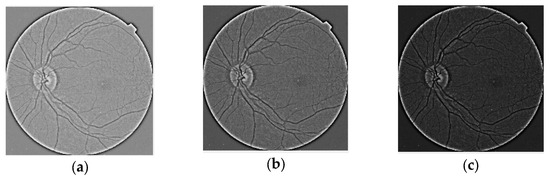
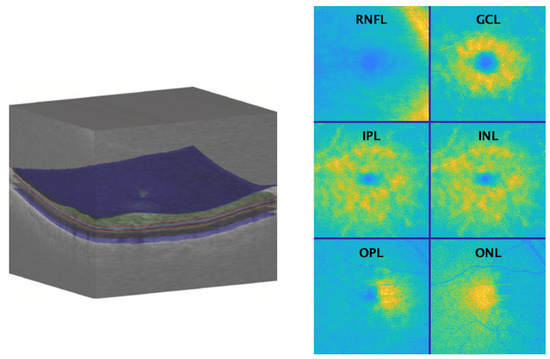
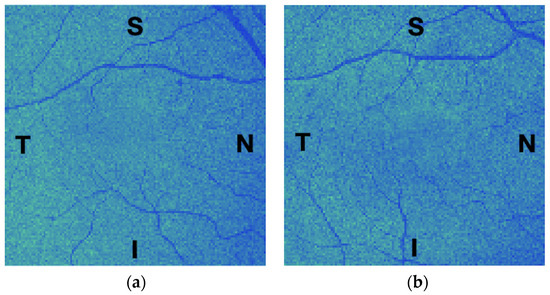
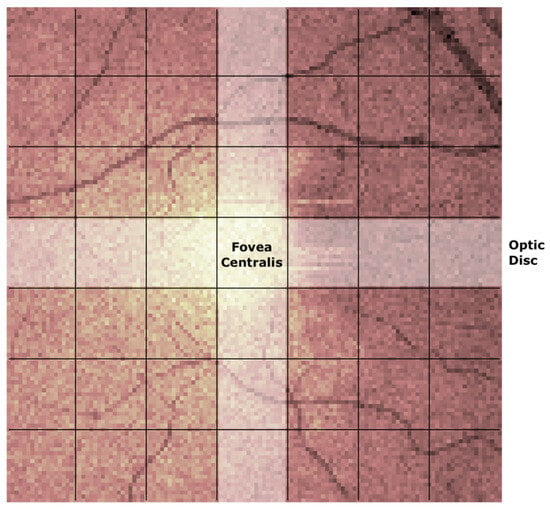
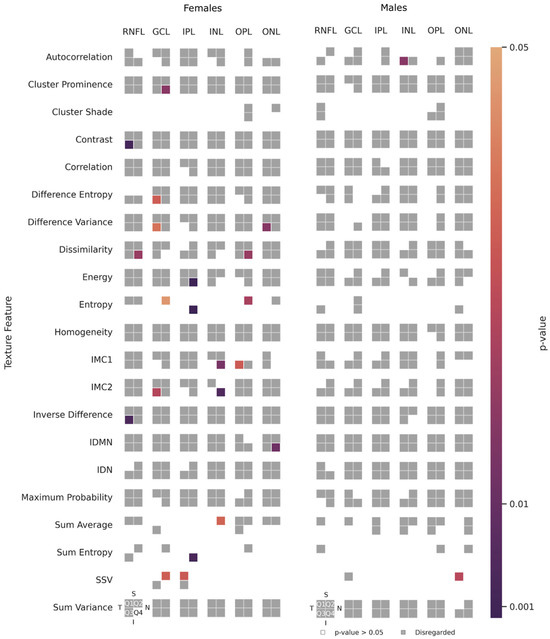
Human body tissue disease diagnosis will become more accurate if transmittance images, such as X-ray images, are separated according to each constituent tissue. This research proposes a new image decomposition technique based on the matrix inverse method for biological tissue images. The fundamental
[...] Read more.
Human body tissue disease diagnosis will become more accurate if transmittance images, such as X-ray images, are separated according to each constituent tissue. This research proposes a new image decomposition technique based on the matrix inverse method for biological tissue images. The fundamental idea of this research is based on the fact that when k different monochromatic lights penetrate a biological tissue, they will experience different attenuation coefficients. Furthermore, the same happens when monochromatic light penetrates k different biological tissues, as they will also experience different attenuation coefficients. The various attenuation coefficients are arranged into a unique
(This article belongs to the Topic Applications in Image Analysis and Pattern Recognition)
►
Show Figures
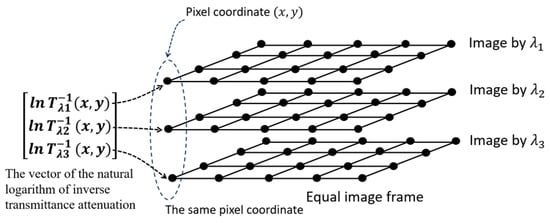
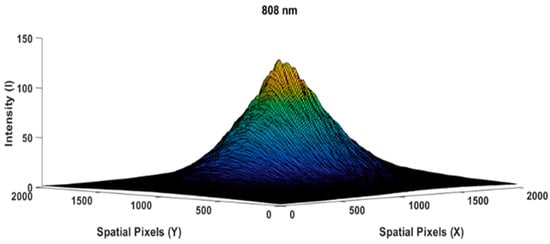
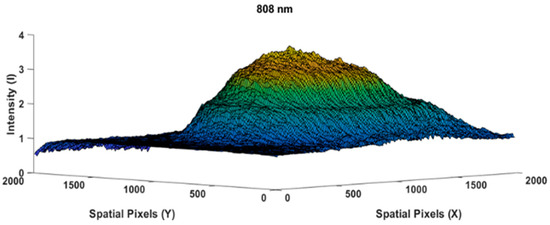
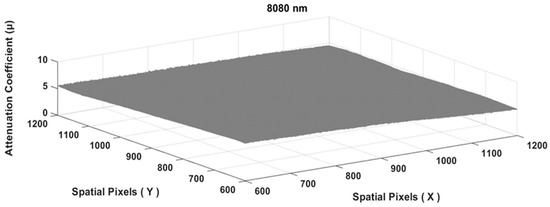
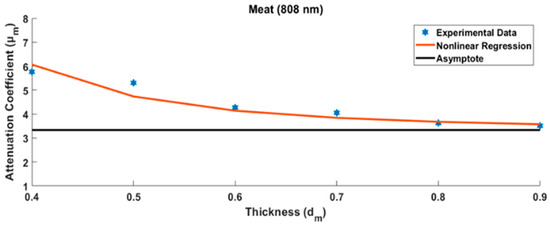
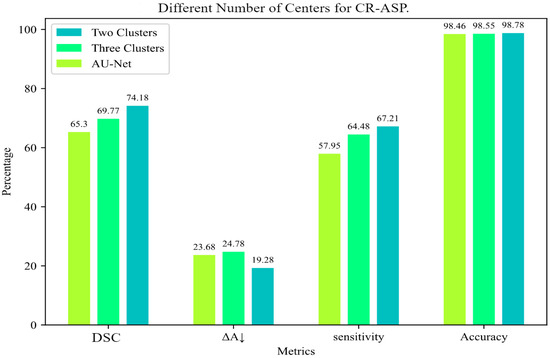
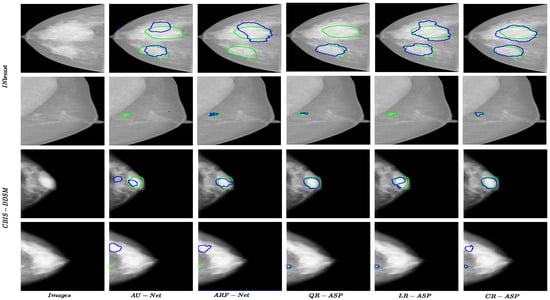
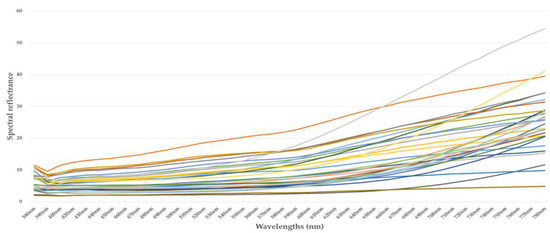
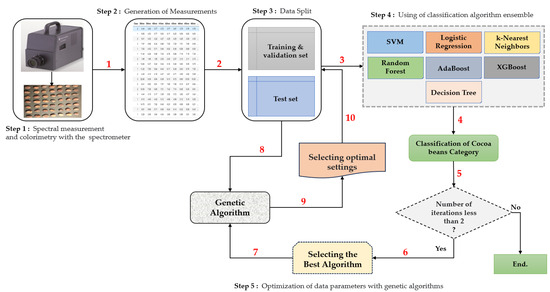
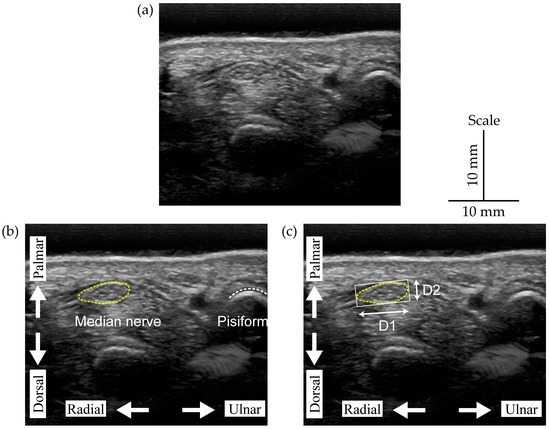
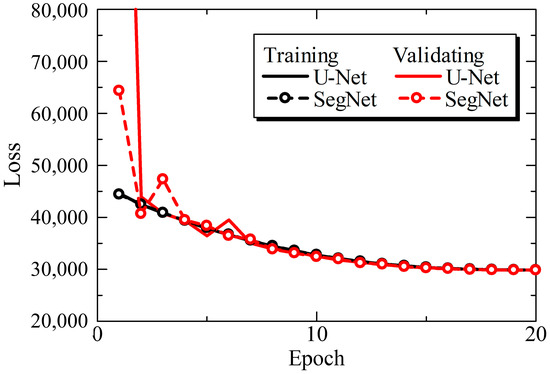
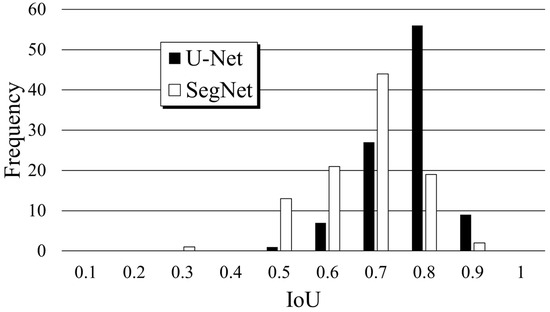
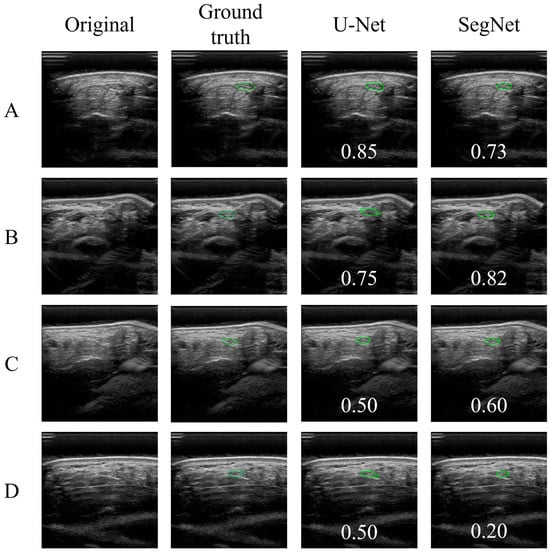
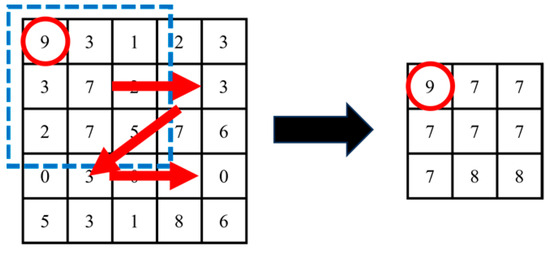
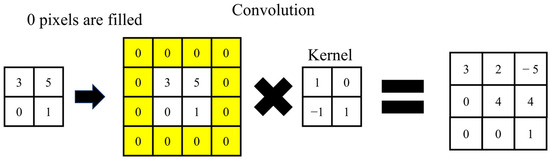
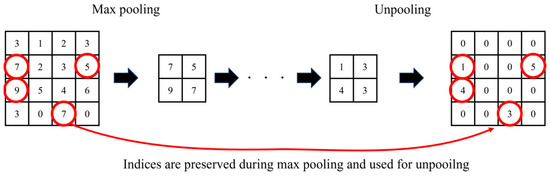
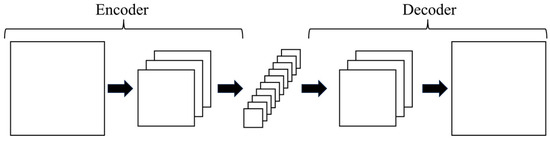
Figure 1



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}