






Mach. Learn. Knowl. Extr. 2024, 6(1), 156-170; https://doi.org/10.3390/make6010009 - 12 Jan 2024
Abstract
The impact of communication through social media is currently considered a significant social issue. This issue can lead to inappropriate behavior using social media, which is referred to as cyberbullying. Automated systems are capable of efficiently identifying cyberbullying and performing sentiment analysis on
[...] Read more.
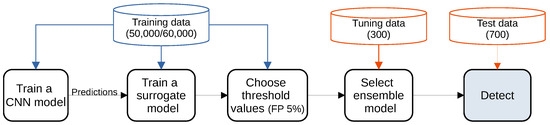
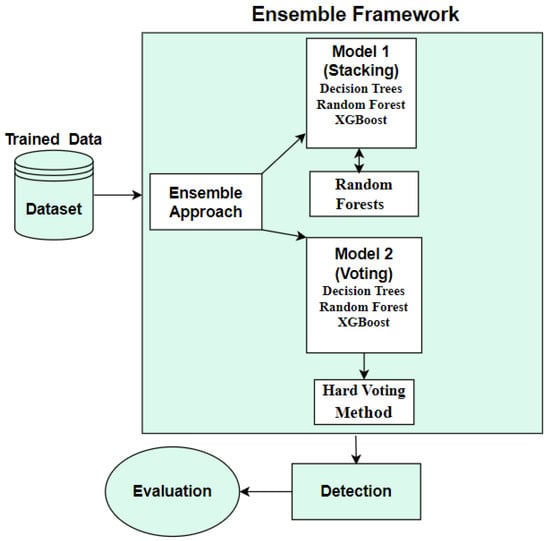
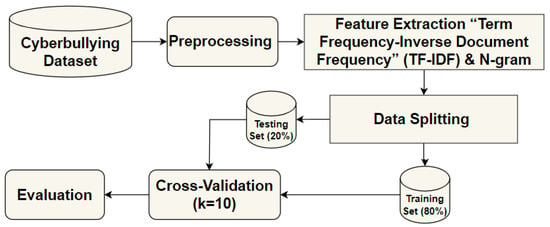
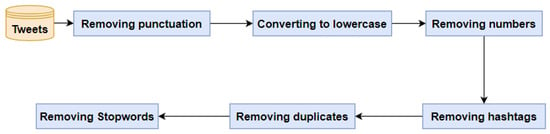
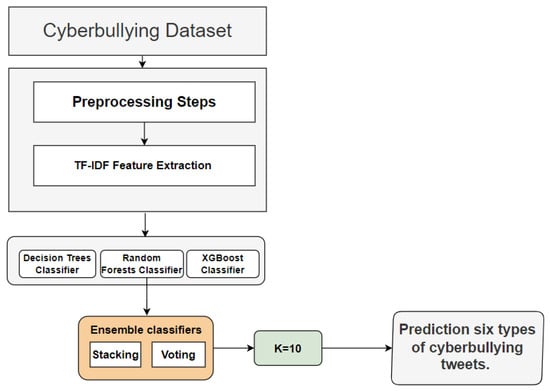
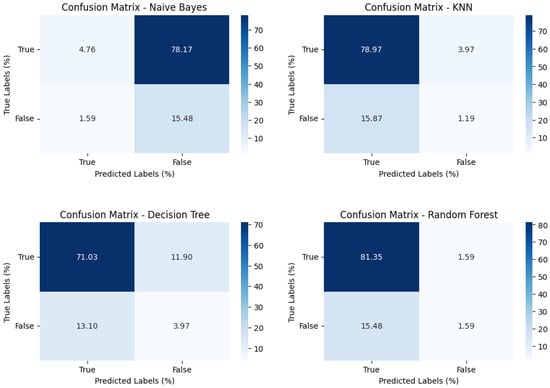
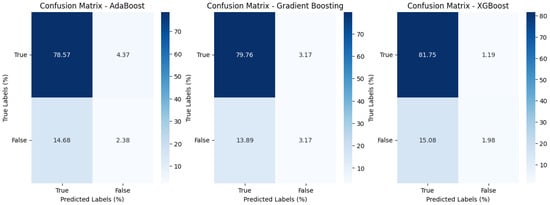
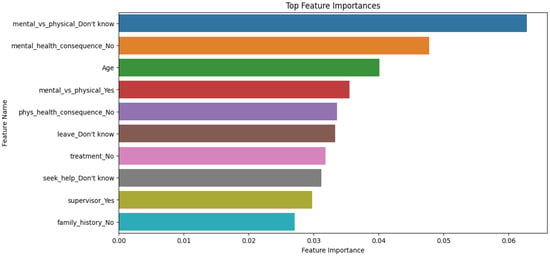
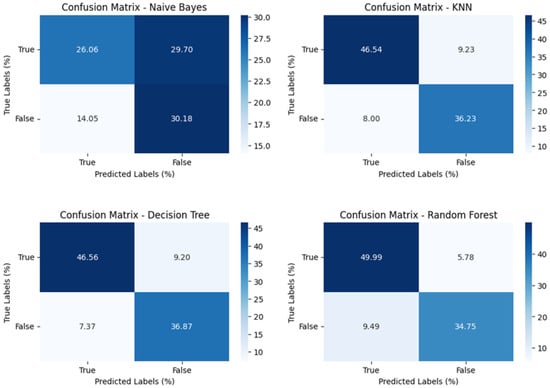
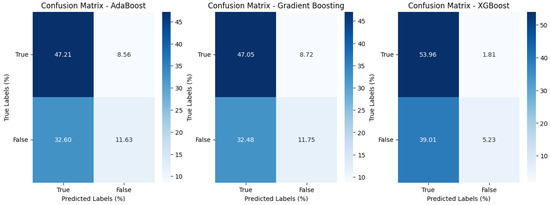
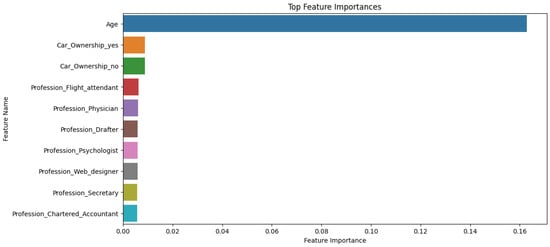
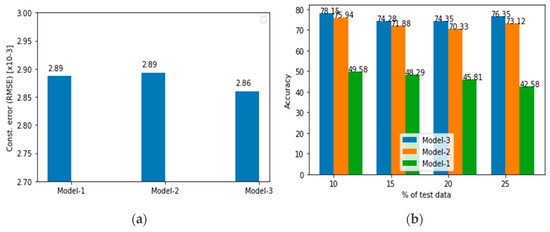
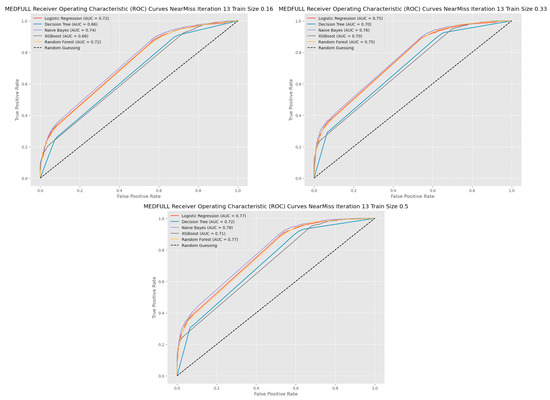
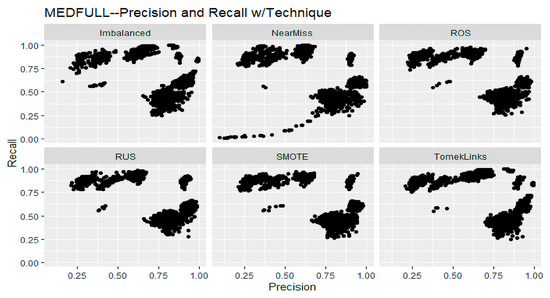
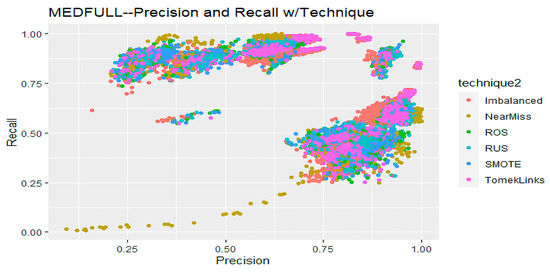
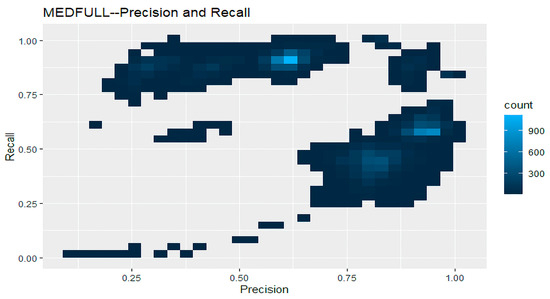
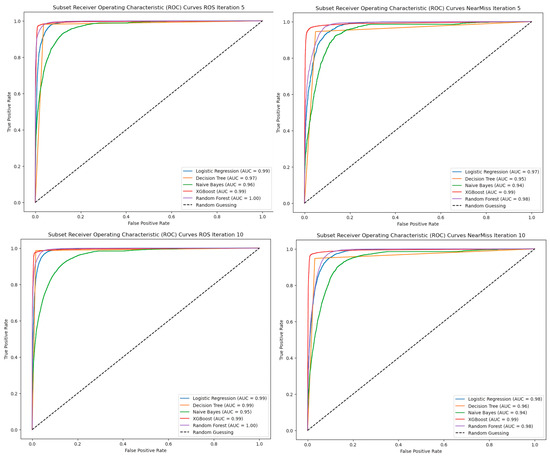
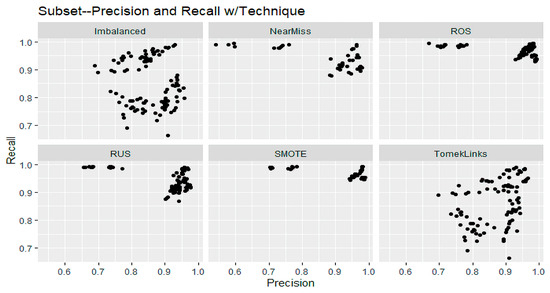
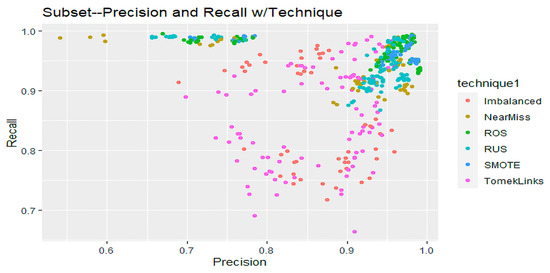
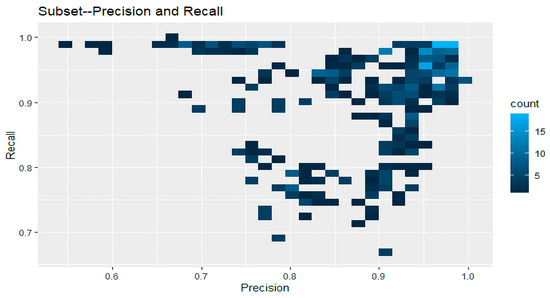
The impact of communication through social media is currently considered a significant social issue. This issue can lead to inappropriate behavior using social media, which is referred to as cyberbullying. Automated systems are capable of efficiently identifying cyberbullying and performing sentiment analysis on social media platforms. This study focuses on enhancing a system to detect six types of cyberbullying tweets. Employing multi-classification algorithms on a cyberbullying dataset, our approach achieved high accuracy, particularly with the TF-IDF (bigram) feature extraction. Our experiment achieved high performance compared with that stated for previous experiments on the same dataset. Two ensemble machine learning methods, employing the N-gram with TF-IDF feature-extraction technique, demonstrated superior performance in classification. Three popular multi-classification algorithms: Decision Trees, Random Forest, and XGBoost, were combined into two varied ensemble methods separately. These ensemble classifiers demonstrated superior performance compared to traditional machine learning classifier models. The stacking classifier reached 90.71% accuracy and the voting classifier 90.44%. The results of the experiments showed that the framework can detect six different types of cyberbullying more efficiently, with an accuracy rate of 0.9071.
Full article
(This article belongs to the Section Privacy)
►
Show Figures
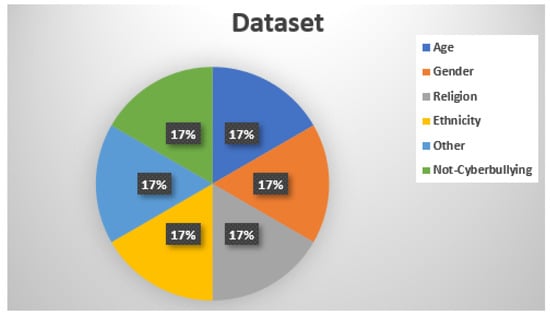
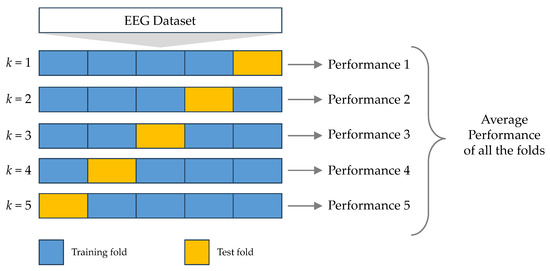
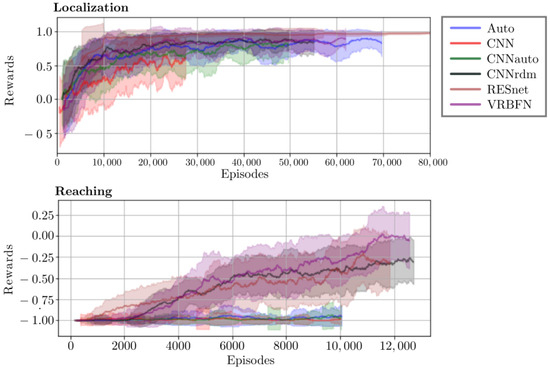
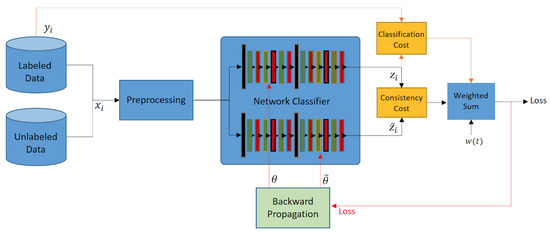
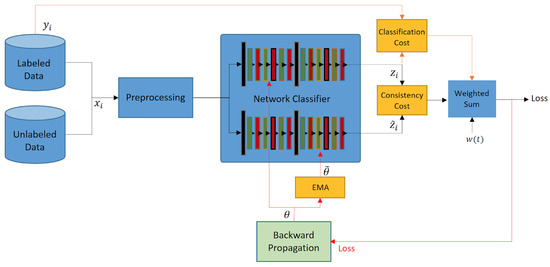
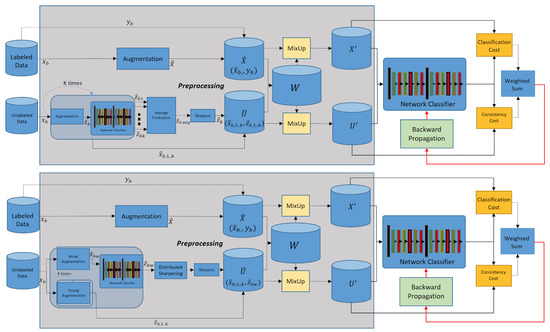
Figure 1












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}